Timeline
An introduction of the steps taken on a timeline
First, how accurate is the NLP model trained in disaster tweets generalized to the classification of disaster estimates in Quotebank? Second, what are the factors that influence the duration of the earthquake in the Quotebank quote from 2008 to 2020?
To answer these questions, we will use a timeline to visualize the steps taken in this section.
-

Always Need More Data!
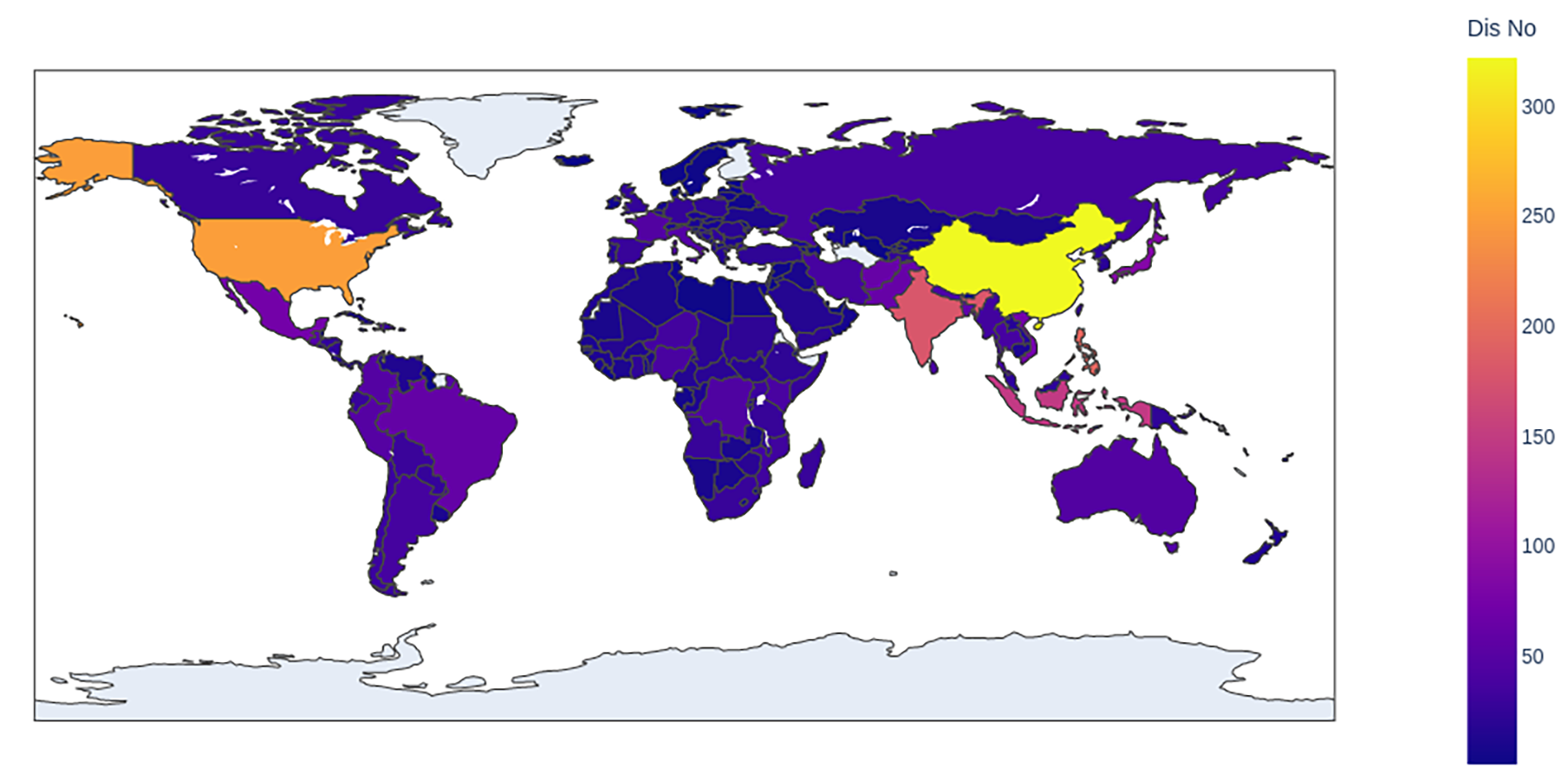
We started with gathering data for our project, preprocessing and visualizing it. We gathered data from indicators of the severity of a disaster, from the development of different countries in different years, from domain geographics and of course, Twitter.
-

NLP Models
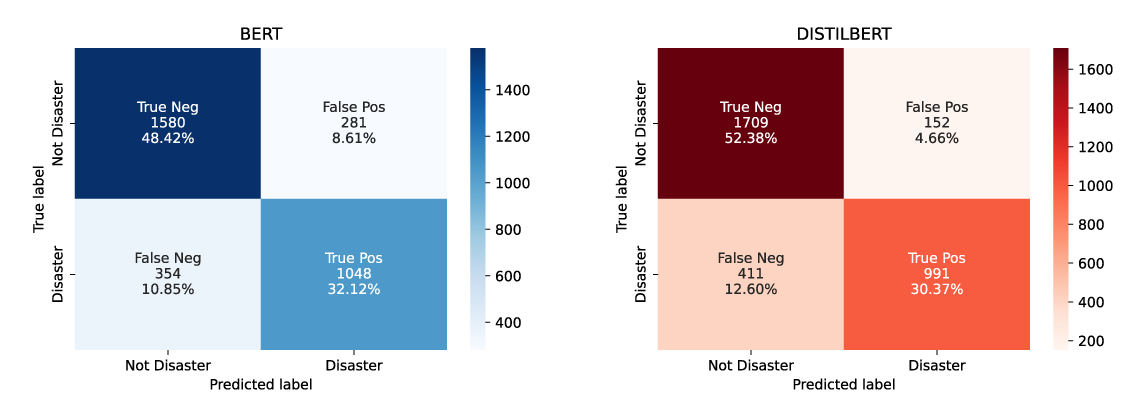
We used a combination of SotA NLP models that are trained on the Twitter Disaster Dataset to detect the disasters in the quotes.
-

Filtering Quotes with RegEx
We also filtered earthquakes from QuoteBank using keyword regex. For the disasters we gathered the most important keywords, such as the associated event name.
-

Media Coverage Analysis
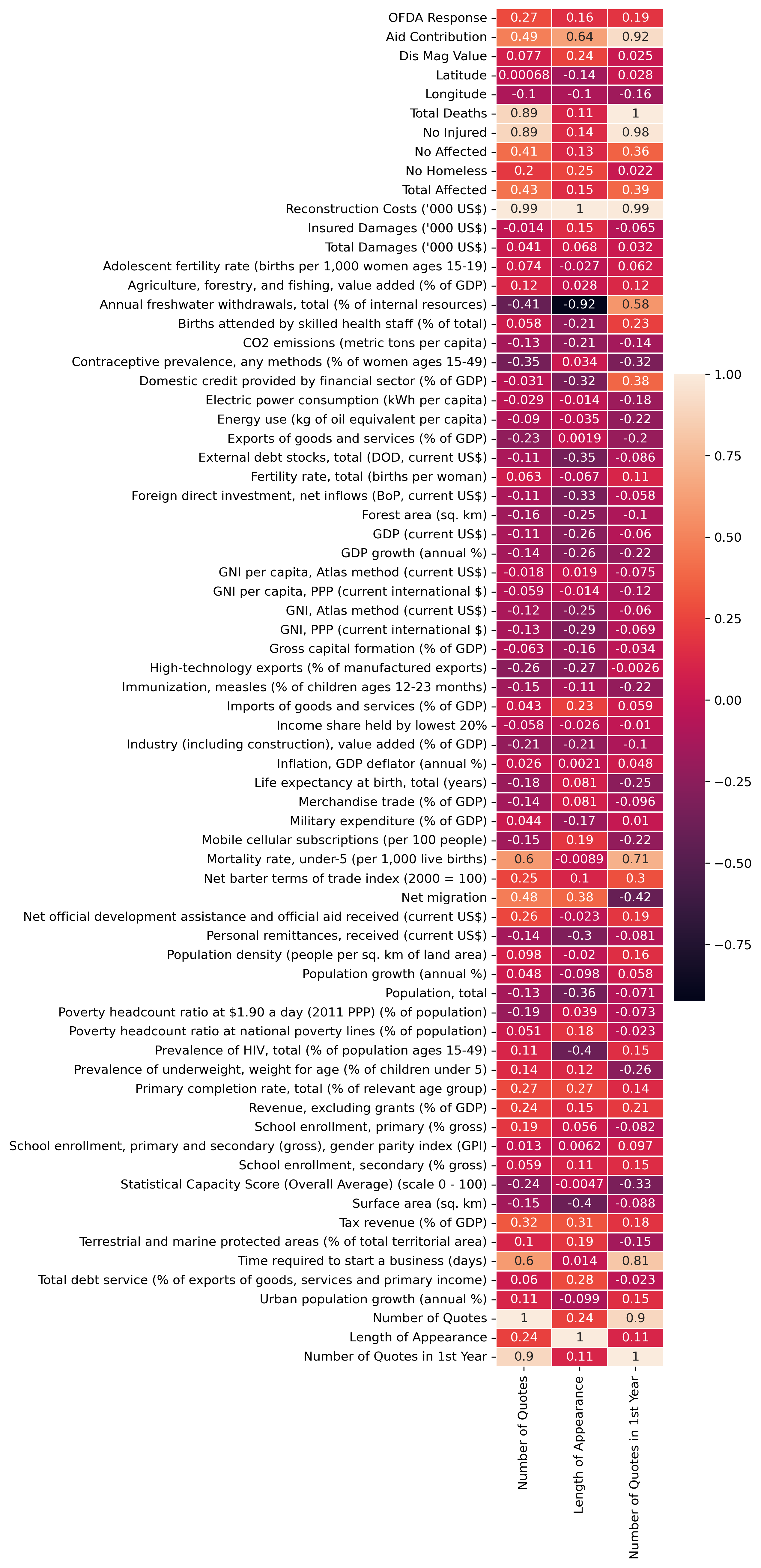
We analyzed in depth the possible factors of how much people talk about these horrible events.
-
How about
some more
details?